멀티 PIVOT
출처
https://stackoverflow.com/questions/27707421/sqlserver-multiple-pivot-on-same-columns
여기에 답변으로 달린..
SELECT ID,
NAME,
Max([Raised to Supplier(PLANED)])[Raised to Supplier(PLANED)],
Max([Base Test Date(PLANED)])[Base Test Date(PLANED)],
Max([Washing Approval(PLANED)])[Washing Approval(PLANED)],
Max([Raised to Supplier(ACTUAL)])[Raised to Supplier(ACTUAL)],
Max([Base Test Date(ACTUAL)])[Base Test Date(ACTUAL)],
Max([Washing Approval(ACTUAL)])[Washing Approval(ACTUAL)]
FROM (SELECT 1 ID,'45rpm' NAME,'Raised to Supplier' + '(PLANED)' MSNAME_pl,'Raised to Supplier' + '(ACTUAL)' MSNAME_ac,'2014-12-17' PLANED,'2015-12-17' ACTUAL
UNION ALL
SELECT 1,'45rpm','Base Test Date' + '(PLANED)','Base Test Date' + '(ACTUAL)','2014-12-18','2015-12-18'
UNION ALL
SELECT 1,'45rpm','Washing Approval' + '(PLANED)','Washing Approval' + '(ACTUAL)','2014-12-19','2015-12-19') a
PIVOT ( Max(PLANED)
FOR MSNAME_pl IN ([Raised to Supplier(PLANED)],
[Base Test Date(PLANED)],
[Washing Approval(PLANED)]) ) AS p1
PIVOT ( MAX(ACTUAL)
FOR MSNAME_ac IN ([Raised to Supplier(ACTUAL)],
[Base Test Date(ACTUAL)],
[Washing Approval(ACTUAL)])) p2
GROUP BY ID, NAME
결과

지금은 쓸일은 없는데...
최근 개발할때 써볼까 했다가... 잘 안되어서...
끝나고 찾아보니 실행가능한 샘플이 있다.
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| mssql] 해당일자의 주간, 월간 시작~끝까지 구하기. (0) | 2025.04.17 |
|---|---|
| SSMS 에러 해결방법!! (0) | 2021.02.16 |
| sqler 문제 풀이. (0) | 2017.05.22 |
| sqler에 올라온 질문글... (0) | 2016.09.12 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
mssql] 해당일자의 주간, 월간 시작~끝까지 구하기.
일일 점검표 같은 걸 만들어줘야 하는데... 월간으로 보여줄지. 주간으로 보여줘야 할지...
범위를 고려해야 하기 때문에 둘다 구하는 쿼리를 샘플로 만들었다.
주간: 해당 일자가 포함된 주간의 일요일 ~ 토요일까지의 일자를 구한다.
월간: 해당 일자가 포함된 월의 1일 ~ 말일까지를 구한다.
* 예전에 만든 쿼리가 있긴 하네...
* 임시테이블에 넣는거...
* 오류 수정 :: 실제 적용해보니 원하던 결과가 아니었다.
04-13일요일을 설정하고 주간 정보를 보면 월요일 부터 나와야 할게 14일부터 보여져서 수정.( 04-23 )
DECLARE @TODAY DATETIME = '2025-04-13 00:00:00'
--SET @TODAY = DATEADD( MINUTE, -(8*60+30), @TODAY )
-- 일요일부터 시작하면 : DATEADD( DAY, - CASE DATEPART(WEEKDAY, @TODAY) WHEN 1 THEN 7 ELSE DATEPART(WEEKDAY, @TODAY) - 1 END + NUMBER, @TODAY)
-- 월요일부터 시작하면 : DATEADD( DAY, - CASE DATEPART(WEEKDAY, @TODAY) WHEN 1 THEN 7 ELSE DATEPART(WEEKDAY, @TODAY) - 1 END + NUMBER + 1, @TODAY)
-- 해당 날자에 주간
SELECT DATEADD( DAY, - CASE DATEPART(WEEKDAY, @TODAY) WHEN 1 THEN 7 ELSE DATEPART(WEEKDAY, @TODAY) - 1 END + NUMBER + 1, @TODAY)
FROM MASTER..SPT_VALUES
WHERE TYPE = 'P'
AND NUMBER BETWEEN 0 AND 6
-- 해당 날자에 월간
SELECT DATEADD( DAY, (-1 * (DATEPART(DAY, @TODAY) - NUMBER - 1)), @TODAY)
, DATENAME(WEEKDAY, DATEADD( DAY, (-1 * (DATEPART(DAY, @TODAY) - NUMBER - 1)), @TODAY))
FROM MASTER..SPT_VALUES
WHERE TYPE = 'P'
AND NUMBER BETWEEN 0 AND DATEPART( DAY, Eomonth( @TODAY ))-1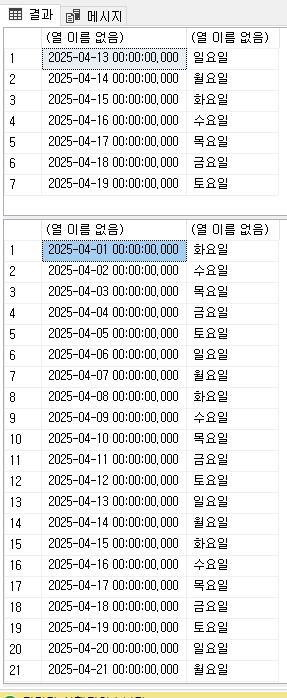
찾아보니 이것도 있네...
set datefirst 1 -- 월요일은 1 화요일은 2 수요일은 3 ... 일요일은 7
[출처] [ms-sql] 일주일의 시작일을 월요일로 정하기|작성자 남짱
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| 멀티 PIVOT (0) | 2025.05.08 |
|---|---|
| SSMS 에러 해결방법!! (0) | 2021.02.16 |
| sqler 문제 풀이. (0) | 2017.05.22 |
| sqler에 올라온 질문글... (0) | 2016.09.12 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
SSMS 에러 해결방법!!
에러 내용 :
ssms를 켜고 솔루션 창이나 출력, 속성창등을 드래그 해서 창을 프로그램에서 꺼낸 후 다시 드래그로
원하는 위치로 넣을때 프로그램이 종료되는 현상.
해결방법 :
docs.microsoft.com/en-us/answers/questions/263738/ssms-188-crashes-when-re-docking-tabs.html
SSMS 18.8 crashes when re-docking tabs - Microsoft Q&A
docs.microsoft.com
VinnieAmir-0621 <---- 이사람 답변
구글번역 :
모든 SSMS 창을 닫고 SQL Mgt Studio EXE 파일을 찾으십시오.
C:\Program Files(x86)\Microsoft SQL Server Management Studio 18\Common7\IDE 찾을 수 없는 경우
SSMS를 여는 데 사용하는 바로 가기를 마우스 오른쪽 단추로 클릭하고 속성> 파일 위치 열기로 이동합니다.
이 파일을 찾으면 "Ssms.exe.config"라는 파일도 찾아서 관리자 모드에서 메모장을 열고이 파일을 편집합니다.
그런 다음 라는 xml 태그를 찾아야하며 다음을 정확히 APPEND (대체 아님)해야합니다.
;Switch.System.Windows.Interop.MouseInput.OptOutOfMoveToChromedWindowFix=true;Switch.System.Windows.Interop.MouseInput.DoNotOptOutOfMoveToChromedWindowFix=true

그리고 그게 다입니다. 이제이 불쾌한 충돌을 피할 수 있습니다.
ps :
새 프로젝트를 시작하면서 기존 노트북이 망가져서 새 노트북에 환경설정을 마쳤었다.
크리스탈 리포트 관련 이슈가 있어서 해결하는 과정에서 ssms를 실행하고 프로시저를 확인하려고
내가 만들어 넣은 오브젝트 탐색기를 가동시켜 프로시저를 찾았는데...
이게 설정 후 처음 열리는 것이라 팝업형태로 떠있길래 드래그 해서 프로그램안으로 밀어넣었는데...
강제종료???
여러번 해봤지만 역시나 에러로 종료되어 내 개발pc에서 확장프로그램 소스를 이용하여 ssms를 열고 동일한 에러가 발생하였다. ssms버젼확인 후 18.5에서 해결되었다는 글을 보고 최신버젼 18.8을 설치하였으나 동일한 증상이 일어났다.
혹시나 하여 14, 16, 17버젼 모두 실행해서 확인해본결과 14빼고 모두 동일하게 강제종료 되었다.
잘 되던게 왜이러나 하고... 고민하던 중에... 내가 만든 것만 그런가? 라는 생각에...
ssms에 원래 있던 창인 "출력" 창을 열어서 드래그해서 붙여보니 ... 동일하게 강제종료 현상이 발생하였다.
다행이 내 프로그램문제는 아니구나 하고 검색... 검색... ....
찾았다. 영어가 안되는게 참 서글픈... 크롬에서 번역기능이 없었으면... 찾았을까 싶다.
머리가 나빠서 쉽지 않은 삶이야...
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| 멀티 PIVOT (0) | 2025.05.08 |
|---|---|
| mssql] 해당일자의 주간, 월간 시작~끝까지 구하기. (0) | 2025.04.17 |
| sqler 문제 풀이. (0) | 2017.05.22 |
| sqler에 올라온 질문글... (0) | 2016.09.12 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
sqler 문제 풀이.
sqler 질문글..
아래처럼 풀이해봤음.
/*
col1 | col2
1 10
2 20
3 30
4 40
*/
;with tb
as
(
select 1 as col1, 10 as col2
union
select 2 as col1, 20 as col2
union
select 3 as col1, 30 as col2
union
select 4 as col1, 40 as col2
)
select case when col = 1 then tmp1.col1 else tmp2.col11 end as col1,
case when col = 1 then tmp1.col2 else tmp2.col22 end as col2
from ( values( 1),( 2 ) ) as tab ( col )
left join
(
select 1 as k, col1, col2
from tb
) as tmp1
on tab.col = tmp1.k
left join
(
select 2 as k, count( col1 ) as col11, sum( col2 ) as col22
from tb
) as tmp2
on tab.col = tmp2.k
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| mssql] 해당일자의 주간, 월간 시작~끝까지 구하기. (0) | 2025.04.17 |
|---|---|
| SSMS 에러 해결방법!! (0) | 2021.02.16 |
| sqler에 올라온 질문글... (0) | 2016.09.12 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.13 |
sqler에 올라온 질문글...
sqler에 질문글..
http://www.sqler.com/bSQLQA/862019
심심해서....
;with tmp
as
(
select *
from
(
values
(1, '2008-01-02 00:00:00.000' ),
(2, NULL),
(3, NULL),
(4, '2008-01-03 00:00:00.000'),
(5, NULL),
(6, NULL),
(7, NULL),
(8, NULL),
(9, '2008-01-04 00:00:00.000'),
(10, NULL),
(11, NULL)
) as tb (a, b )
)
select a, isnull( b , ( select max( b ) from tmp where a < bs.a )) as bb
from tmp as bs
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| SSMS 에러 해결방법!! (0) | 2021.02.16 |
|---|---|
| sqler 문제 풀이. (0) | 2017.05.22 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.13 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.11 |
Sqler에 있는 질문에 대해 풀어봤다.
피벗으로 하는 건데...
문제 차제가 조금 데이타가 부족해보였다.
그림에 보이는데로 나오는 걸 일부 수정해서 풀었지만...
동적으로 늘어나는 데이타 컬럼에 대해서 처리를 위해 동적쿼리를 만들어야 되는데...
과연? 얼마나 사이즈가 늘어날지는 실 데이타로 처리 해봐야 하니 .. 모르겠고,
문제 : http://www.sqler.com/828698#1
## 첫풀이 : 공백으로 처리 했지만 char(10)으로 바꾸면 enter값을 넣어서 뿌리는 건 비슷하게 나온다.
;with tb
as
(
SELECT ITEM_CD, SPEC, SO_DT + ' ' + DLVY_DT + ' '+ SOLD_TO_PARTY_NM as HD, SO_QTY
FROM (
VALUES
( '41-P006-IVM', 'GAP-6 IV', '2016-05-10', '2016-05-13', 'TMEH-J', 2400 ),
( '41-P006-IVM', 'GAP-6 IV', '2016-05-12', '2016-05-20', 'TMEH-J', 4800 ),
( '41-P006-IVM', 'GAP-6 IV', '2016-05-17', '2016-05-20', 'TMEH-J', 10800 ),
( '41-P006-IVM', 'GAP-6 IV', '2016-05-13', '2016-05-20', 'AXIS', 2400 )
) AS TB ( ITEM_CD, SPEC, SO_DT, DLVY_DT, SOLD_TO_PARTY_NM, SO_QTY )
)
SELECT *
from tb
pivot
(
sum( SO_QTY ) for HD in (
[2016-05-13 2016-05-20 AXIS],
[2016-05-10 2016-05-13 TMEH-J],
[2016-05-12 2016-05-20 TMEH-J],
[2016-05-17 2016-05-20 TMEH-J]
)
) as pt
## 두번째 풀이 : 헤더값을 결과로 만들어 Union 처리 하는 방법.
;with tb
as
(
SELECT ITEM_CD, SPEC, SO_DT, DLVY_DT, SOLD_TO_PARTY_NM, SO_QTY
FROM (
VALUES
( '41-P006-IVM', 'GAP-6 IV', '2016-05-10', '2016-05-13', 'TMEH-J', 2400 ),
( '41-P006-IVM', 'GAP-6 IV', '2016-05-12', '2016-05-20', 'TMEH-J', 4800 ),
( '41-P006-IVM', 'GAP-6 IV', '2016-05-17', '2016-05-20', 'TMEH-J', 10800 ),
( '41-P006-IVM', 'GAP-6 IV', '2016-05-13', '2016-05-20', 'AXIS', 2400 )
) AS TB ( ITEM_CD, SPEC, SO_DT, DLVY_DT, SOLD_TO_PARTY_NM, SO_QTY )
), src
as
(
select ITEM_CD, SPEC, SO_DT + ' ' + DLVY_DT +' '+ SOLD_TO_PARTY_NM as HD, SO_QTY
from tb
), hd1
as
(
select ITEM_CD, SPEC, SO_DT + ' ' + DLVY_DT +' '+ SOLD_TO_PARTY_NM as HD, SO_DT
from tb
)
, hd2
as
(
select ITEM_CD, SPEC, SO_DT + ' ' + DLVY_DT +' '+ SOLD_TO_PARTY_NM as HD, DLVY_DT
from tb
)
, hd3
as
(
select ITEM_CD, SPEC, SO_DT + ' ' + DLVY_DT +' '+ SOLD_TO_PARTY_NM as HD, SOLD_TO_PARTY_NM
from tb
)
select *, 1 as odr--ITEM_CD, SPEC, [2016-05-13 2016-05-20 AXIS],[2016-05-10 2016-05-13 TMEH-J],[2016-05-12 2016-05-20 TMEH-J],[2016-05-17 2016-05-20 TMEH-J]
from hd1
pivot
(
min( SO_DT ) for HD in (
[2016-05-13 2016-05-20 AXIS],
[2016-05-10 2016-05-13 TMEH-J],
[2016-05-12 2016-05-20 TMEH-J],
[2016-05-17 2016-05-20 TMEH-J]
)
) as pt
union
select *, 2 as odr--ITEM_CD, SPEC, [2016-05-13 2016-05-20 AXIS],[2016-05-10 2016-05-13 TMEH-J],[2016-05-12 2016-05-20 TMEH-J],[2016-05-17 2016-05-20 TMEH-J]
from hd2
pivot
(
min( DLVY_DT ) for HD in (
[2016-05-13 2016-05-20 AXIS],
[2016-05-10 2016-05-13 TMEH-J],
[2016-05-12 2016-05-20 TMEH-J],
[2016-05-17 2016-05-20 TMEH-J]
)
) as pt
union
select *, 3 as odr--ITEM_CD, SPEC, [2016-05-13 2016-05-20 AXIS],[2016-05-10 2016-05-13 TMEH-J],[2016-05-12 2016-05-20 TMEH-J],[2016-05-17 2016-05-20 TMEH-J]
from hd3
pivot
(
min( SOLD_TO_PARTY_NM ) for HD in (
[2016-05-13 2016-05-20 AXIS],
[2016-05-10 2016-05-13 TMEH-J],
[2016-05-12 2016-05-20 TMEH-J],
[2016-05-17 2016-05-20 TMEH-J]
)
) as pt
union
select ITEM_CD, SPEC,
convert(varchar,[2016-05-13 2016-05-20 AXIS]),
convert(varchar,[2016-05-10 2016-05-13 TMEH-J]),
convert(varchar,[2016-05-12 2016-05-20 TMEH-J]),
convert(varchar,[2016-05-17 2016-05-20 TMEH-J]),
9999 as odr
from src
pivot
(
sum( SO_QTY ) for HD in (
[2016-05-13 2016-05-20 AXIS],
[2016-05-10 2016-05-13 TMEH-J],
[2016-05-12 2016-05-20 TMEH-J],
[2016-05-17 2016-05-20 TMEH-J]
)
) as pt
order by odr

'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| sqler 문제 풀이. (0) | 2017.05.22 |
|---|---|
| sqler에 올라온 질문글... (0) | 2016.09.12 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.13 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.11 |
| 경고: 집계 또는 다른 ... 어쩌고 저쩌고 (0) | 2016.02.17 |
Sqler에 있는 질문에 대해 풀어봤다.
문제1 ) http://www.sqler.com/827048#4
/* 100000과 가장 가까운 근사치값을 구할때 */
select n, v, abs( v - 100000 )
from (
values
(1, 1000 ),
(2, 2300 ),
(3, 1000 ),
(4, 5000 ),
(5, 16000 ),
(6, 54000 ),
(7, 8200 ),
(8, 1500 ),
(9, 2555 )
) as tb( n, v )
order by 3
이렇게 하면 가장 가까운게 위로 올라온다.
문제2 ) http://www.sqler.com/bSQLQA/827651
피봇으로 데이타를 만들때 내부 데이타가 집계가 아닌 실제 원소데이타를 포함하도록 뿌려달라는 것 같다.
declare @ttb table
(
TESTBENCH int,
TESTWEEK varchar(100),
TESTNAME varchar(100)
)
insert into @ttb
select *
from
(
values
(1, 'W1618.1', 'TEST1'),
(1, 'W1618.1', 'TEST2'),
(1, 'W1618.1', 'TEST3'),
(1, 'W1618.2', 'TEST1'),
(1, 'W1618.3', 'TEST2'),
(2, 'W1618.2', 'TEST1'),
(2, 'W1618.2', 'TEST3'),
(2, 'W1618.3', 'TEST2'),
(2, 'W1618.4', 'TEST2'),
(2, 'W1618.4', 'TEST3')
) as tb (TESTBENCH, TESTWEEK, TESTNAME )
declare @TESTBENCH int
declare @W1 varchar(100), @W2 varchar(100), @W3 varchar(100), @W4 varchar(100)
declare @result table
(
TESTBENCH int,
[W1618.1] varchar(100),
[W1618.2] varchar(100),
[W1618.3] varchar(100),
[W1618.4] varchar(100)
)
declare rst cursor
for
select TESTBENCH, [W1618.1], [W1618.2], [W1618.3], [W1618.4]
from @ttb
pivot
(
count( TESTNAME ) for TESTWEEK in ( [W1618.1], [W1618.2], [W1618.3], [W1618.4] )
) as p
OPEN rst
FETCH NEXT FROM rst
INTO @TESTBENCH, @W1, @W2, @W3, @W4
WHILE @@FETCH_STATUS = 0
BEGIN
select @W1 = '', @W2 = '', @W3 = '', @W4 = ''
select @W1 += TESTNAME + char(10)
from @ttb
where TESTBENCH = @TESTBENCH
and TESTWEEK = 'W1618.1'
select @W2 += TESTNAME + char(10)
from @ttb
where TESTBENCH = @TESTBENCH
and TESTWEEK = 'W1618.2'
select @W3 += TESTNAME + char(10)
from @ttb
where TESTBENCH = @TESTBENCH
and TESTWEEK = 'W1618.3'
select @W4 += TESTNAME + char(10)
from @ttb
where TESTBENCH = @TESTBENCH
and TESTWEEK = 'W1618.4'
insert into @result
select @TESTBENCH, @W1, @W2, @W3, @W4
FETCH NEXT FROM rst
INTO @TESTBENCH, @W1, @W2, @W3, @W4
END
CLOSE rst;
DEALLOCATE rst;
select *
from @result

커서를 이용하면 되긴 하는데 고정 컬럼으로 만들었을때 위와 같고, 가변적으로 해야 할때는 부분부분 function으로 동작할수 있게 하고 줄여서
동적 쿼리로 만들어주면 된다.
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| sqler에 올라온 질문글... (0) | 2016.09.12 |
|---|---|
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.11 |
| 경고: 집계 또는 다른 ... 어쩌고 저쩌고 (0) | 2016.02.17 |
| MS-SQL] 코드트리 + 상세내역에 코드별 합계쿼리. (0) | 2013.02.26 |
Sqler에 있는 질문에 대해 풀어봤다.
세번째 풀이
sqler를 들려보니 각 일별로 분을 만든게 떠있네? 음...
그래서 다시 만들어봤다. 1시간 소요 ㅠㅠ... 만들어 놓은걸 안보고 해봤음. ( 보고 싶은 유혹이... )
역시나 아직 내가 놓치는 부분들이 있네.

;with ttb as
(
select DATEADD( HOUR, -8, convert( datetime, st )) as st, DATEADD( HOUR, -8, convert( datetime, ed)) as ed
from
(
values
( '2016-05-09 09:00:00', '2016-05-09 09:30:00' ),
( '2016-05-09 23:00:00', '2016-05-10 09:00:00' ),
( '2016-05-10 22:20:00', '2016-05-11 05:00:00' ), -- 테스트를 위해 추가.
( '2016-05-12 22:20:00', '2016-05-15 05:00:00' ) -- 테스트를 위해 추가.
) as tb ( st, ed)
/* 문제 :
이와같은 데이터가 있을때 합산하는 시점은 오전 08시로 기준을 잡고
2016-05-09 : 570분 (9:00 ~ 09:30 = 30분 + 23:00 ~ 익일 08:00 = 540분)
2016-05-10 : 60분 (기준시간 08:00~ 09:00 = 60분)
이렇게 SELECT 를 하고싶은데요.. 너무헷갈립니다 고수분들 조언부탁 드립니다.
*/
), otb ( st, ed )
as
(
select DATEADD( hour, -8, convert( datetime, st )) as st,
DATEADD( hour, -8, convert( datetime, ed )) as ed
from ttb
)
, rtb ( diff, dt )
as
(
select DATEDIFF( day, min( st ), max( ed ) ) as diff, convert( datetime, convert( varchar(10), min( st ), 121 )) as dt
from otb
)
, jtb ( dt1 , dt2)
as
(
select DATEADD( Day, number, dt ) as dt1, dateadd( MILLISECOND, -2, DATEADD( Day, number + 1, dt )) as dt2
from rtb, (
select number
from master.dbo.spt_values
where name is null ) as ntb
where ntb.number <= rtb.diff
)
select dt1, dt2, case when st is null then 0
else
case when dt1 <= st then st else dt1 end
end as st
, case when ed is null then 0
else case when ed < dt2 then ed else dt2 end
end as ed,
datediff( MINUTE,
case when st is null then 0
else
case when dt1 <= st then st else dt1 end
end,
case when ed is null then 0
else case when ed < dt2 then ed else dt2 end
end )
as diff
from jtb
left
outer join otb
on ( otb.ed > jtb.dt1 and otb.st < jtb.dt2 )
/###############################################################################/
아래가 문제인데...
08시를 기준으로 시작시간, 종료시간 분(시간) 구하기.
우선 급한데로 풀이를 한다면... 아래처럼 구해보겠다. 테스트 까지 1시간 조금 안걸린듯....
첫번째 풀이
;with ttb as
(
select convert( datetime, st ) as st, convert( datetime, ed) as ed
from
(
values
( '2016-05-09 09:00:00', '2016-05-09 09:30:00' ),
( '2016-05-09 23:00:00', '2016-05-10 09:00:00' ),
( '2016-05-10 22:20:00', '2016-05-11 05:00:00' ) -- 테스트를 위해 추가.
) as tb ( st, ed)
/* 문제 :
이와같은 데이터가 있을때 합산하는 시점은 오전 08시로 기준을 잡고
2016-05-09 : 570분 (9:00 ~ 09:30 = 30분 + 23:00 ~ 익일 08:00 = 540분)
2016-05-10 : 60분 (기준시간 08:00~ 09:00 = 60분)
이렇게 SELECT 를 하고싶은데요.. 너무헷갈립니다 고수분들 조언부탁 드립니다.
*/
)
select dt, sum( case when m > 0 then m else 0 end) as sum_m
from
(
SELECT convert( varchar(10), st, 121) as dt,
case when DATEDIFF( DAY, st, ed ) > 0 and CONVERT( datetime, CONVERT( varchar(10), ed , 112) + ' 08:00:00' ) < ed then DATEDIFF( MINUTE, st, CONVERT( datetime, CONVERT( varchar(10), ed , 112) + ' 08:00:00' ) )
else DATEDIFF( MINUTE, st, ed)
end as m
FROM ttb
UNION ALL
SELECT convert( varchar(10), ed, 121) as dt,
DATEDIFF( MINUTE, CONVERT( datetime, CONVERT( varchar(10), ed , 112) + ' 08:00:00' ), ed ) as m
FROM ttb
WHERE DATEDIFF( DAY, st, ed ) > 0 and CONVERT( datetime, CONVERT( varchar(10), ed , 112) + ' 08:00:00' ) < ed
) s
group by dt
두번재 풀이 ( 10분만에 썼음. )
위 식에서 다음날 08시 기준이니까 -8시간 하면 00시 정각이 되니 이것으로 시간을 구함.
;with ttb as
(
select DATEADD( HOUR, -8, convert( datetime, st )) as st, DATEADD( HOUR, -8, convert( datetime, ed)) as ed
from
(
values
( '2016-05-09 09:00:00', '2016-05-09 09:30:00' ),
( '2016-05-09 23:00:00', '2016-05-10 09:00:00' )
-- ( '2016-05-10 22:20:00', '2016-05-11 05:00:00' ) -- 테스트를 위해 추가.
) as tb ( st, ed)
/* 문제 :
이와같은 데이터가 있을때 합산하는 시점은 오전 08시로 기준을 잡고
2016-05-09 : 570분 (9:00 ~ 09:30 = 30분 + 23:00 ~ 익일 08:00 = 540분)
2016-05-10 : 60분 (기준시간 08:00~ 09:00 = 60분)
이렇게 SELECT 를 하고싶은데요.. 너무헷갈립니다 고수분들 조언부탁 드립니다.
*/
)
select dt, sum( case when m > 0 then m else 0 end) as sum_m
from
(
select convert( varchar(10), st, 121) as dt, DATEDIFF( MINUTE, st, ed ) - case when DATEDIFF( DAY, st, ed ) >= 1 then DATEDIFF( MINUTE, CONVERT( datetime, CONVERT( varchar(10), ed , 112) + ' 00:00:00' ), ed ) else 0 end as m
from ttb
union all
select convert( varchar(10), ed, 121) as dt, DATEDIFF( MINUTE, CONVERT( datetime, CONVERT( varchar(10), ed , 112) + ' 00:00:00' ), ed )
from ttb
where DATEDIFF( DAY, st, ed ) > 0
) s
group by dt
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.20 |
|---|---|
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.13 |
| 경고: 집계 또는 다른 ... 어쩌고 저쩌고 (0) | 2016.02.17 |
| MS-SQL] 코드트리 + 상세내역에 코드별 합계쿼리. (0) | 2013.02.26 |
| MS-SQL] sp_helptxt 만들기... (0) | 2012.11.22 |
경고: 집계 또는 다른 ... 어쩌고 저쩌고
이번에 많은 일을 하는 프로시져 하나가 자꾸 실행중에 죽는다는 얘기를 들었다.
음... WCF 패킷이 깨지면서 오류가 뜬다.
ProtocolException ...
그런데 Sql 매니지먼트에서 돌리면 잘 돈다. ( 그러나, 메세지 창에 "경고 : 집계 또는 다른 SET ... " 이란 경고 문구가 엄청 많이 출력되었다. )
구글링 겁나 하다보니...
저런 메세지가 발생할때 윈도우 시스템에 이벤트시스템과 연계되어 성능이 느려질 수 있다고 한다.
그래서 얘기 했더니 없어지도록 쿼리를 수정하고 성능도 오류도 모두 사라졌다!!!
WCF 메세지 패킷 사이즈도 저거때문에 깨지는게 아니었을까???
참고.. http://blog.naver.com/PostView.nhn?blogId=nhsang&logNo=40127532573
https://msdn.microsoft.com/ko-kr/library/system.servicemodel.protocolexception(v=vs.110).aspx
ProtocolException 클래스 : 데이터 전송 프로토콜이 일치하지 않아 원격 상대방과 통신할 수 없는 경우 throw되어 클라이언트에 나타나는 예외입니다.
>> https://social.msdn.microsoft.com/Forums/vstudio/en-US/77097d1f-372a-4c7d-910f-57c9ecd9c5c1/the-maximum-string-content-length-quota-8192-has-been-exceeded-while-reading-xml-data-this-quota?forum=wcf
>> https://social.msdn.microsoft.com/Forums/en-US/f5c3fdeb-65da-4d72-90eb-4c5c31e582d1/nonwcf-service-responds-with-wrong-contentlength-header-protocolexception?forum=wcf
>> WCF 설정에서 예외처리상세여부?
http://stackoverflow.com/questions/8434206/getting-a-faultexception-when-trying-to-work-with-a-wcf-service
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.13 |
|---|---|
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.11 |
| MS-SQL] 코드트리 + 상세내역에 코드별 합계쿼리. (0) | 2013.02.26 |
| MS-SQL] sp_helptxt 만들기... (0) | 2012.11.22 |
| MS-SQL] 테이블 스키마 생성 추출 쿼리. (0) | 2012.11.21 |
MS-SQL] 코드트리 + 상세내역에 코드별 합계쿼리.
느룡...
좀더 빠른 쿼리는 없을까낭...
쿼리 속도가 빨라짐!! 장실에서 일보다 생각났음 ㅡ.,ㅡv
테이블 관계를 다시 확인하고, 가공해야 할 최소단위 데이타로 만들어서
58000여건에 대해 쿼리문을 적용하니 40sec -> 2sec 줄었음.
결과

;WITH CBS AS (
SELECT *
FROM (
VALUES
('A', '코드A', '', 1),
('A.01', '코드A1', 'A', 2),
('A.02', '코드A2', 'A', 2),
('A.01.01', '코드A01', 'A.01', 3),
('A.01.02', '코드A02', 'A.02', 3)
) AS CBS ( CODE , CODENAME, UPPER_CODE, CODE_LEVEL)
),
DETAIL AS
(
SELECT *
FROM (
VALUES
('0001', '코드A.01.01.0001', 'A.01.01', 10),
('0002', '코드A.01.01.0002', 'A.01.01', 20),
('0003', '코드A.01.02.0003', 'A.01.02', 30),
('0004', '코드A.01.02.0004', 'A.01.02', 40),
('0005', '코드A.01.02.0005', 'A.01.02', 50)
) AS CBS ( CODE , CODENAME, CBS_CODE, QUANTITY )
)
,
TOTAL AS
(
SELECT SUBSTRING( CBS_CODE+ '.', 0, CHARINDEX( '.', CBS_CODE + '.')) AS CODE1 ,
SUBSTRING( cbs_code+ '.', 0, CHARINDEX( '.', cbs_code + '.', CHARINDEX( '.', cbs_code+ '.')+1) ) as code2,
CBS_CODE AS CODE3,
CODE AS CODE4,
CODENAME,
QUANTITY
FROM DETAIL
)
SELECT CODE1 ,
'' CODE_NAME,
SUM(QUANTITY),
CODE1 + '.00.00' AS ALIGN
FROM TOTAL t inner join CBS c
on t.CODE1 = c.CODE and c.CODE_LEVEL = 1
GROUP BY CODE1
UNION ALL
SELECT CODE2,
'' CODE_NAME,
SUM(QUANTITY) ,
CODE2 + '.00' AS ALIGN
FROM TOTAL t inner join CBS c
on t.CODE2 = c.CODE and c.CODE_LEVEL = 2
GROUP BY CODE1, CODE2
UNION ALL
SELECT CODE3,
'' CODE_NAME,
SUM(QUANTITY) ,
CODE3 AS ALIGN
FROM TOTAL t inner join CBS c
on t.CODE3 = c.CODE and c.CODE_LEVEL = 3
GROUP BY CODE1, CODE2, CODE3
UNION ALL
SELECT CODE4,
CODENAME,
SUM(QUANTITY) ,
CODE3 + CODE4 AS ALIGN
FROM TOTAL
GROUP BY CODE1,
CODE2,
CODE3,
CODE4,
CODENAME
ORDER BY ALIGN
'# 7) 데이타베이스 > Ms-Sql' 카테고리의 다른 글
| Sqler에 있는 질문에 대해 풀어봤다. (0) | 2016.05.11 |
|---|---|
| 경고: 집계 또는 다른 ... 어쩌고 저쩌고 (0) | 2016.02.17 |
| MS-SQL] sp_helptxt 만들기... (0) | 2012.11.22 |
| MS-SQL] 테이블 스키마 생성 추출 쿼리. (0) | 2012.11.21 |
| MS-SQL] SP_JS_시리즈... (0) | 2012.03.02 |
